
ObsidianとCursor(Antigravity)を連携し、記事制作を効率化する中で、WordPressで作成した記事をObsidianに取り込み、過去記事のリライトなどをしたいな~と思い、記事ごとにマークダウンファイルとしてObsidian内に一括変換してみた。本記事では、その手順を公開します。

WordPressから記事をエクスポートする
まずは記事の取得ですが、これは簡単。
WordPress管理画面のメニューから「ツール」を選択し、その中の「エクスポート」を選ぶ。
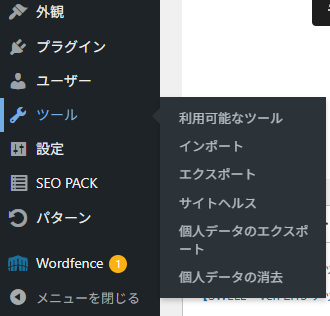
筆者は「SWELL」を採用しています。
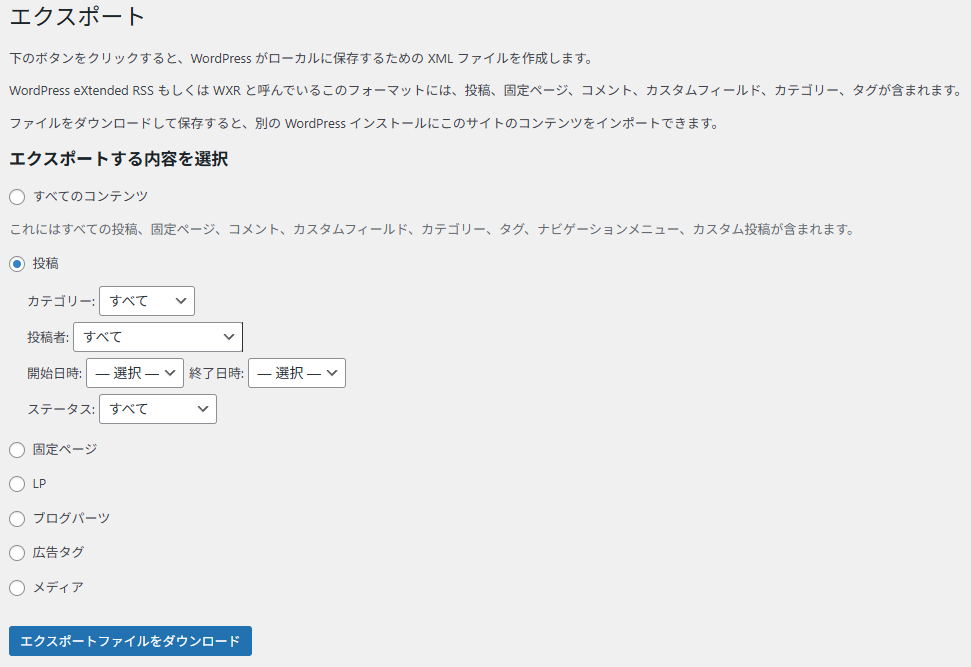
▲こんな画面が開くので、投稿にチェックを入れてダウンロードするだけ。
カテゴリーや投稿者などで、ダウンロードする記事をフィルタリングすることもできます。
XMLファイルをマークダウンファイルに変換する
さて、問題はここから。
ダウンロードした記事は「XML(WordPressのエクスポート用データ)」という形式。
そのままだとObsidianで読みやすい形ではなく、1記事ごとにも分かれていない。
よって、Obsidianでも見られる&AIフレンドリーなマークダウン形式に変換し、さらに記事ごとにファイル分けするためのプログラムを作成し、Cursor(Antigravityも可)のターミナルで実行することにした。(これも全部AIに聞いただけなのだが。笑)
Python および 必要パッケージ(markdownfy)のインストール
プログラムコードはPythonで書いて実行するため、まずはPythonがPCにインストールされているか、さらに実行環境が整っているかを、以下コマンドで確認。
python –version
python -m pip –version

コマンド実行を、▲のようにバージョン情報が表示されればOK。
未インストールの場合は公式からダウンロードする。
AIを利用しているとPythonを利用することが多い気がするので、後々のことを考えてインストールしておくのがオススメ。もちろん無料。
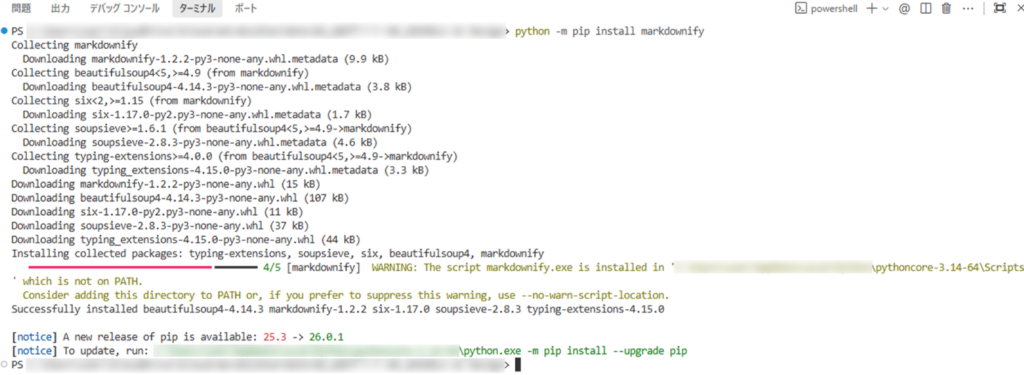
Pythonがインストールされていることを確認したら、以下コマンドを実行し、マークダウン形式に変換するためのソフトをインストールする。
python -m pip install markdownify
作業用フォルダでPythonプログラムを実行
インストールが終わったら、作業用フォルダを新規作成し、そこにWordPressからダウンロードしたXMLファイルを移動する。フォルダやファイル名は以下の通り。
- 作業用フォルダ名:wp-md
- XMLファイル名:wordpress-export.xml
CursorまたはAntigravityで作業用フォルダを開き、以下コードを記載したPythonファイル(wp_xml_to_md.py)を作成する。
import os
import re
import xml.etree.ElementTree as ET
from markdownify import markdownify as md
INPUT_XML = "wordpress-export.xml"
OUTPUT_DIR = "markdown_posts"
NS = {
"content": "http://purl.org/rss/1.0/modules/content/",
"wp": "http://wordpress.org/export/1.2/",
}
def sanitize_filename(name: str) -> str:
name = re.sub(r'[\\/:*?"<>|]', '', name)
name = re.sub(r'\s+', '-', name.strip())
return name[:120] if name else "untitled"
def clean_markdown(text: str) -> str:
text = text.replace('\r\n', '\n').replace('\r', '\n')
text = re.sub(r'\n{3,}', '\n\n', text)
return text.strip() + "\n"
def main():
os.makedirs(OUTPUT_DIR, exist_ok=True)
tree = ET.parse(INPUT_XML)
root = tree.getroot()
channel = root.find("channel")
if channel is None:
print("channel が見つかりません。XML形式を確認してください。")
return
count = 0
for item in channel.findall("item"):
title = item.findtext("title", default="Untitled")
post_type = item.findtext("wp:post_type", default="", namespaces=NS)
status = item.findtext("wp:status", default="", namespaces=NS)
post_date = item.findtext("wp:post_date", default="", namespaces=NS)
post_name = item.findtext("wp:post_name", default="", namespaces=NS)
if post_type not in ["post", "page"]:
continue
content_el = item.find("content:encoded", NS)
html = content_el.text if content_el is not None and content_el.text else ""
if not html.strip():
continue
markdown = md(html, heading_style="ATX")
markdown = clean_markdown(markdown)
slug_base = post_name if post_name else title
filename = sanitize_filename(slug_base) + ".md"
path = os.path.join(OUTPUT_DIR, filename)
frontmatter = [
"---",
f'title: "{title.replace(chr(34), chr(39))}"',
f'type: "{post_type}"',
f'status: "{status}"',
f'date: "{post_date}"',
"---",
"",
]
with open(path, "w", encoding="utf-8") as f:
f.write("\n".join(frontmatter))
f.write(markdown)
count += 1
print(f"{count}件のMarkdownファイルを {OUTPUT_DIR} に出力しました。")
if __name__ == "__main__":
main()これで準備完了!
そのままターミナルを開き、以下コマンドを実行。
python wp_xml_to_md.py

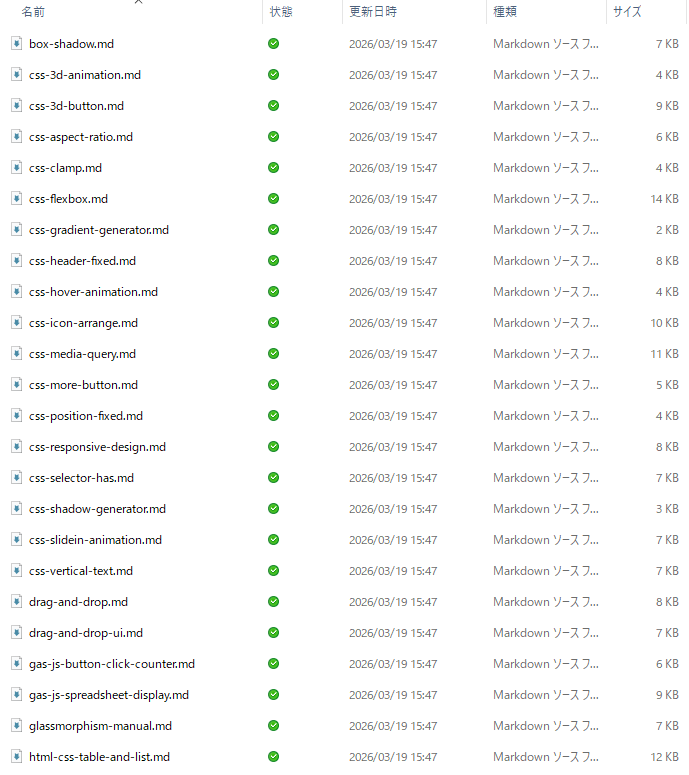
作業フォルダに「markdown_posts」というフォルダが作成され、記事別のマークダウンファイルを作成できました!

まとめ
- WordPressの管理画面 「ツール」→「エクスポート」で記事をダウンロード(XMLファイル)
- CursorまたはAntigravityのターミナルでPython環境を確認し、
markdownifyをインストール - 作業用フォルダにXMLファイルと変換用Pythonファイルを置き、ターミナルで実行
Pythonはほぼ触ったことがなかったけど、AIがちゃちゃっと完璧なコードを用意してくれたので楽ちん。Pythonはもともとインストール済ということもあって、5分くらいで終わったかな?
これで各記事をObsidianで見られるし、AIでの編集や読み込みもしやすくなった!
早速、過去記事のリライトを進めていこうっと!






